Китайский исследователь предложил принципиально новый подход к оценке количества параметров в языковых моделях. В отличие от традиционных методов, таких как экономика инференса, новый бенчмарк основывается на анализе фактических знаний модели, а не на её рассудочных способностях. Это связано с тем, что фактические знания, в отличие от когнитивных навыков, не поддаются эффективному сжатию и ограничены энтропией Шеннона.
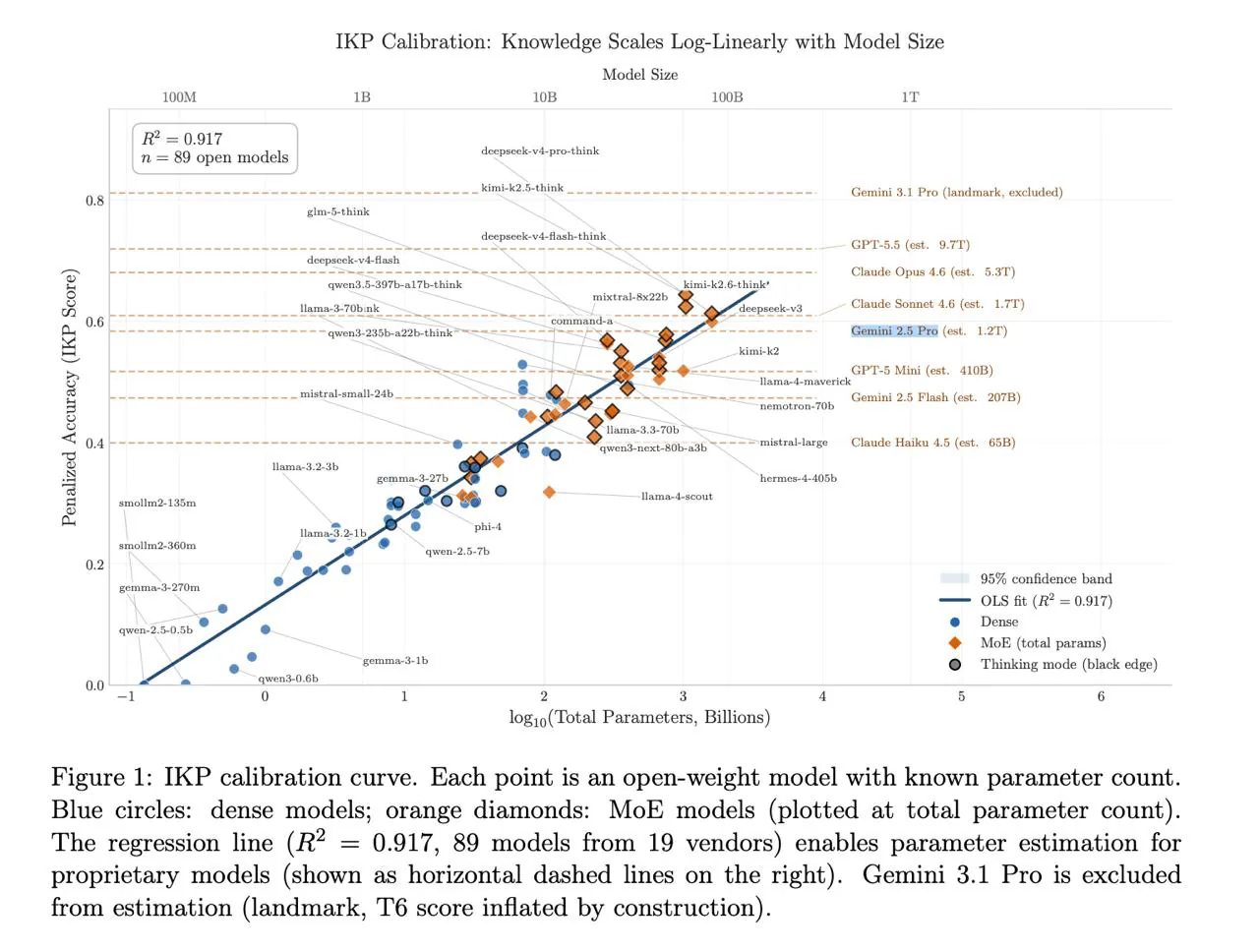
Автором была разработана методология, предполагающая использование бенчмарка из 1400 вопросов, охватывающих факты различной редкости — от широко известных до крайне специализированных. Калибровка проводилась на 89 открытых моделях с известным числом параметров. Результаты показали явную лог-линейную зависимость между количеством правильных ответов на вопросы и числом параметров модели, с коэффициентом детерминации R²=0,917.
На основе полученной зависимости исследователь оценил количество параметров в ряде закрытых моделей. Согласно расчётам, GPT-5.5 может насчитывать около 9,7 трлн параметров, Claude Opus 4.6 — 5,3 трлн, Claude Sonnet 4.6 — 1,7 трлн, а Gemini 2.5 Pro — 1,2 трлн. При этом автор отмечает, что такие оценки следует рассматривать как нижние границы, поскольку некоторые модели могут отказываться отвечать на определённые вопросы из-за настроек безопасности.
Предложенный метод, несмотря на ограниченную точность, открывает новые возможности для анализа закрытых моделей, которые ранее оставались недоступными для независимых исследований.
Внимание: обмен криптовалют через проверенный обменник.
