


Алгоритмы формирования таких сводок непрозрачны, а значит у пользователя нет понимания, почему система выбрала именно эти источники и именно такую интерпретацию ответа. Возникает вопрос объективности: корректно ли ИИ отражает суть запроса или лишь собирает наиболее вероятную версию на основе доступных данных.
Раньше пользователь сам управлял процессом выбора. Он видел список ссылок, сравнивал источники, читал разные позиции и формировал собственное мнение. Теперь первое прикосновение к вопросу создаёт алгоритм. Даже если человек продолжит поиск дальше, начальная рамка уже задана машиной.
Это особенно чувствительно для брендов и экспертов. Интернет переполнен неточностями, устаревшими данными и откровенными фейками. Если ИИ опирается на такие материалы, они получают дополнительную поддержку, потому что выглядят как «официальный ответ системы». В такой модели ошибка алгоритма перестает быть просто технической неточностью — она может напрямую влиять на репутацию, доверие и экономические показатели.
Тем не менее формальные метрики пока выглядят успокаивающе. По данным исследования журнала JurisDigital:
— Традиционные органические результаты всё ещё получают чуть больше половины кликов — около 51%, даже если расположены ниже ИИ-обзора. При этом 45% пользователей взаимодействуют с блоком генеративного ответа: 19% нажимают «Подробнее», 15% переходят по ссылке внутри ИИ-ответа и ещё 11% кликают по упоминаниям источников.
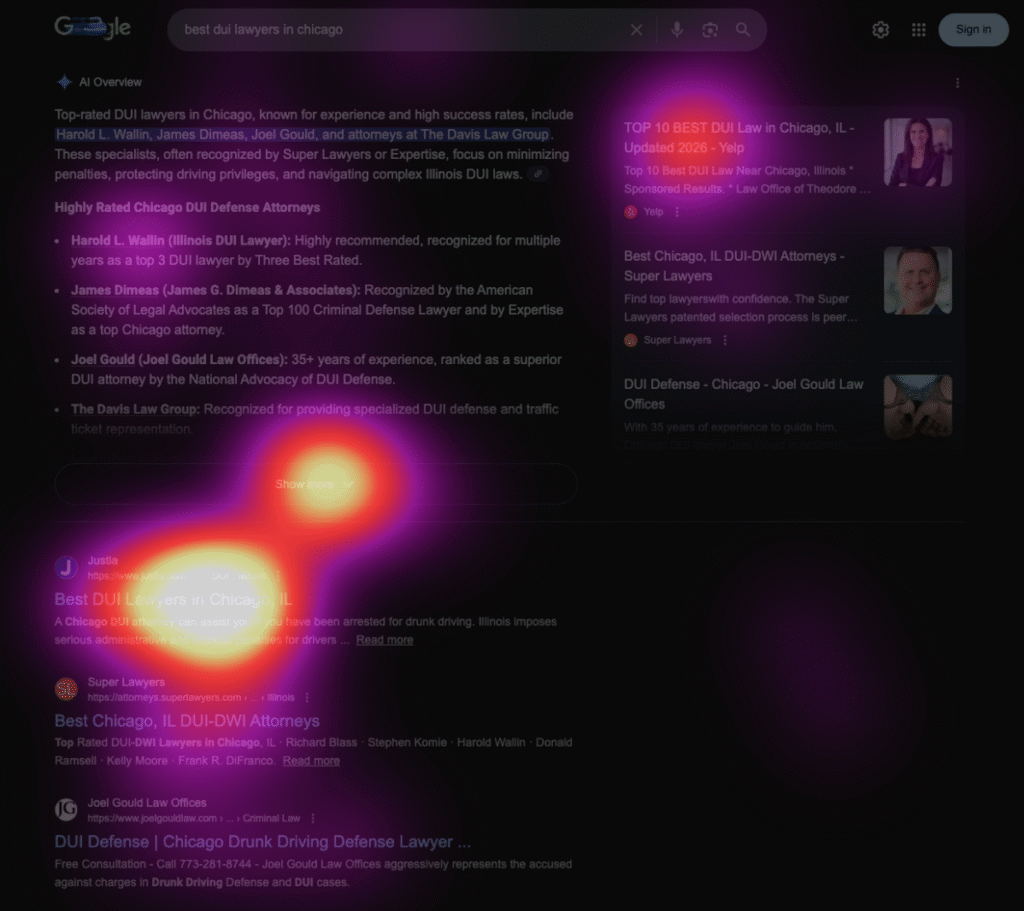
Заметим, что визуальное внимание концентрируется именно в зоне ИИ-сводки. Это означает, что даже если итоговый клик уходит в органику, первичное восприятие запроса формируется алгоритмом. Пользователь сначала читает машинное резюме, и только потом принимает решение, куда переходить дальше.
Для брендов это критично: ИИ-обзор становится первым касанием с аудиторией. Если в нём допущена неточность, упрощение или искажение смысла, именно эта версия закрепляется в сознании пользователя как базовая. А в условиях, когда интернет переполнен спорной и устаревшей информацией, алгоритм может невольно легитимизировать фейковые или вторичные интерпретации.
Именно поэтому вопрос сегодня уже не только в распределении кликов, а в контроле над первым впечатлением. Даже небольшое смещение внимания в сторону ИИ-сводок меняет архитектуру доверия в поиске.
Поэтому главный вопрос сегодня не в том, нужен ли ИИ в поиске, а в том, какие механизмы контроля, прозрачности и ответственности появятся вокруг его решений. Пока эти правила не сформулированы, напряжение между удобством для пользователя и рисками для контентного рынка будет только расти.
